
In this article, we will explore the features, methods, and performance characteristics of HashMap in Java, allowing you to leverage its power in your Java applications.
What is HashMap in Java?
HashMap is a widely used data structure in Java that provides an efficient way to store and retrieve key-value pairs. It is part of the Java Collections Framework and offers a convenient way to store and retrieve data based on unique keys. HashMap has been the default Map used by almost all the Java developers whenever they use a Map. It is Hash table based implementation of the Map interface.It stores the key-value pairs(entries) in buckets.
Why use HashMap in Java?
HashMap in Java is widely used for several reasons:
- Efficient Data Retrieval: Java HashMap provides fast access to elements based on their unique keys. It uses hashing techniques to store and retrieve data in constant time complexity (O(1)) on average.
- Flexible Key-Value Storage: HashMap in Java allows the storage of key-value pairs, where each key is unique. This makes it suitable for scenarios where data needs to be associated with specific identifiers.
- Dynamic Size: HashMap dynamically resizes itself to accommodate more elements as needed. It automatically adjusts its capacity to maintain efficient performance, making it suitable for handling dynamic data sets.
- Implementation of Hashing Algorithms: HashMap implements various hashing algorithms internally, ensuring efficient distribution and retrieval of elements, even for large data sets.
- Wide Range of Applications: HashMap in Java is used in various areas of software development, including caching, indexing, data processing, and implementing associative arrays. Its versatility makes it suitable for a wide range of use cases.
Commonly used Methods : HashMap in Java
Commonly used methods of HashMap in Java are mentioned below
| Method | Description |
|---|---|
put(key, value) | Associates the specified value with the specified key in the map. |
get(key) | Returns the value to which the specified key is mapped. |
containsKey(key) | Returns true if the map contains the specified key. |
containsValue(value) | Returns true if the map contains the specified value. |
remove(key) | Removes the mapping for the specified key from the map. |
isEmpty() | Returns true if the map is empty. |
size() | Returns the number of key-value mappings in the map. |
keySet() | Returns a set of all keys in the map. |
values() | Returns a collection of all values in the map. |
entrySet() | Returns a set of all key-value mappings in the map. |
clear() | Removes all key-value mappings from the map. |
putAll(map) | Copies all of the mappings from the specified map to this map. |
What are Buckets?
HashMap in Java internally uses an Array of Entries(Entry<K,V>[] table) to store the key-value pairs.Each index of the above array is called a Bucket.For example, table[0] is the referred as Bucket 0, table[1] as Bucket 1 and so on.
Entry is an inner class of HashMap. It contains the hashcode of the key, key, value and the reference of the next Node.
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
}
If more than one entry(key-value pair) ends up in the same bucket then those entries are stored in a linked list.The main array only contains the first entry of the linked list.

Capacity and Load-Factor
Capacity is the number of the buckets in the Map.The default capacity is 16. Load factor is a measurement of how full hash table is allowed or number of elements in the hash table. The default load factor is 0.75.
We can assign the capacity and load factor while creating a HashMap in the following way:
Map<K,V> map = new HashMap<K,V>(int initialCapacity, float loadFactor);
For example, Map<String,String> map = new HashMap<String,String>(20,0.8);// here capacity-20, and load factor-0.8
What is the use of load factor?
When, number of entries in the Map > (Threshold= current capacity * load factor) then
HashMap automatically doubles its capacity and already stored entries are re-hashed for even distribution of entries across new buckets.
Internal Working of HashMap in Java
In this section, we will understand the internal working of HashMap in Java using a simple example.
It is easier to understand a concept when we use examples to reduce the complexity. We will take a very simple example here. Let’s say we want store the population of a city in the Map. Now city name is the key and population is the value. Let us create the below map for our purpose.
Map<String,Long> map = new HashMap<String,Long>(8,0.75);
Here we the given the initial capacity as 8 and the load factor as 0.75.A HasMap with 8 buckets is created. All the buckets initially contain null Entry.

So the Threshold = capacity * load factor = 8 * 0.75 = 6. It means when we will try to put the 7th entry the HashMap will double it’s capacity to 16.
Let us add the first entry, map.put(“Delhi”,100000);
The first thing to do is to find the bucket.
In Java 8, the bucket index is calculated by the following formula:
Bucket index= (n – 1) & hashcode of key. Here n is the number of buckets. & -> is bitwise AND operator.
In our case, n = 8 and hashcode of Delhi is 65915436(please check hashcode of String class).
Bucket index = 7 & 65915436 = 4, so the entry will go to Bucket 4. Bucket 4 does not have any entry, so the new entry will be put in Bucket 4.

Let us add the 2nd entry, map.put(“Kolkata”,200000);
Hashcode of Kolkata is 1124159915.
Bucket index = 7 & 1124159915 = 3, so the entry will go to Bucket 3. Bucket 3 does not have any entry, so the new entry will be put in Bucket 3.

Similarly, let us put (“Bangalore”, 100000)- Bucket 7;(“Mangalore”, 100000)- Bucket 2 and (“Chennai”, 300000)- Bucket 0.

Let us put one more entry- 6th entry, (“Kochi”,100000); Hashcode of Kochi is 72669344.
Bucket index = 7 & 72669344 = 0.
Now Bucket 0 already contains an entry (“Chennai”,300000).
HashMap uses equals() method to check if any entry for the same key is already there in the identified bucket. In our case, it checks if there is already any entry for “Kochi” in the Bucket 0.In this case, there is no such entry. So Kochi needs to be put in the Bucket 0.
This leads to hashing collision which means more than one entry in the same bucket.In that case entries are stored in a linked list. So Kochi entry is set as Next of Chennai entry.
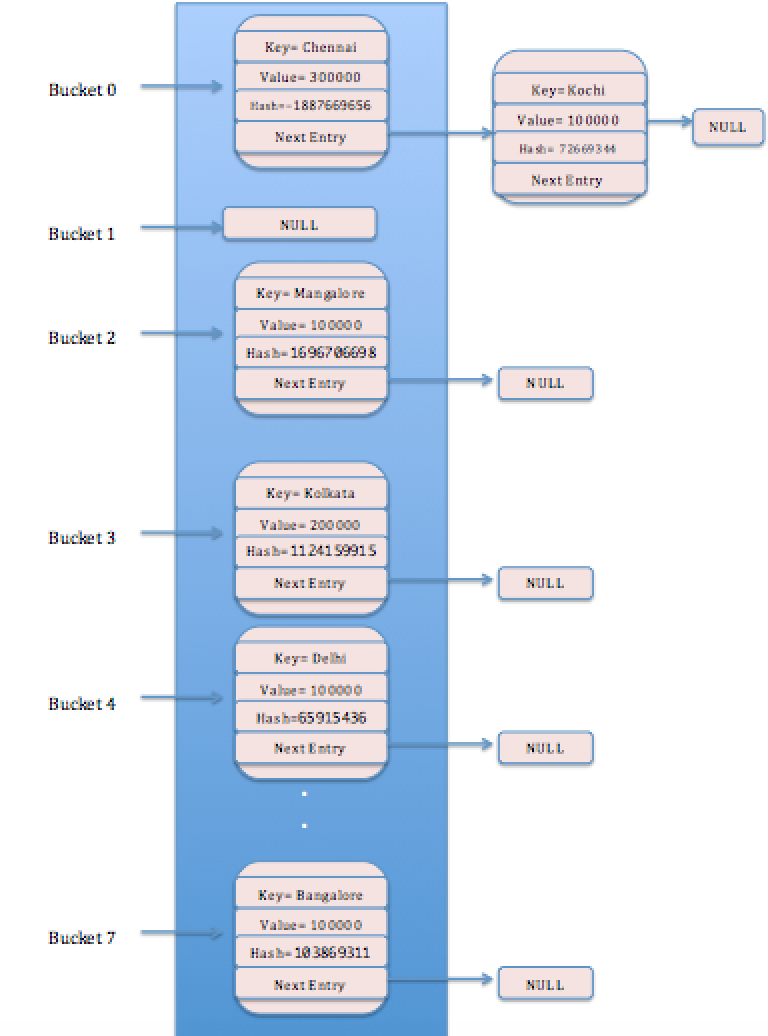
Let’s try to put the entry again for Kolkata with updated population; map.put(“Kolkata”,500000);
Hashcode of Kolkata is 1124159915 so, Bucket index = (7 & 1124159915) = 3;
HashMap finds that there is already one entry in Bucket 3. It uses equals() method to check if the already inserted entry is for the same key “Kolkata”. equals() returns true here. So HashMap will not create a new entry, it just updates the Value attribute of the existing entry.

Let us put one more entry , map.put(“Patna”,200000);
Hashcode of Patna is 76886390 so, Bucket index = (7 & 76886390) = 6;
Bucket 6 does not have any entry, so a new entry needs to be created and put in Bucket 6.
Hey wait, we already have inserted 6 entries and the current threshold[capacity(8)* load factor(.75)] is 6. The threshold is breached now.Now HashMap would double it’s capacity , all entries will be re-hashed and distributed again in the Buckets.
The new capacity = old capacity * 2 = 8 * 2 =16.
New threshold= new capacity * load factor = 16 * 0.75 = 12
Let us figure out the Buckets for the existing entries and for Patna again:
Bucket index= (n – 1) & hashcode of key. Now n=16
| Entry | Capacity(n) =8 Old Bucket Index = (n-1) & hash | Capacity(n) =16 New Bucket Index = (n-1) & hash |
| Key= Delhi Value=100000 Hash=65915436 | 7 & 65915436 = 4 | 15 & 65915436 = 12 |
| Key= Kolkata Value=500000 Hash= 1124159915 | 7 & 1124159915 = 3 | 15 & 1124159915 = 11 |
| Key= Bangalore Value=100000 Hash=103869311 | 7 & 103869311 = 7 | 15 & 103869311 = 15 |
| Key= Mangalore Value=100000 Hash=1696706698 | 7 & 1696706698 = 2 | 15 & 1696706698 = 10 |
| Key= Chennai Value=300000 Hash=-1887669656 | 7 & -1887669656 = 0 | 15 & -1887669656 = 8 |
| Key= Kochi Value=100000 Hash= 72669344 | 7 & 72669344 = 0 | 15 & 72669344 = 0 |
| Key= Patna Value=200000 Hash=76886390 | 7 & 76886390 = 6 | 15 & 76886390 = 6 |
Earlier, entries for Kochi and Chennai were in the same Bucket 0. Now they are distributed to different Bucket. Kochi: Bucket 0 and Chennai: Bucket 8.

Let us summarise the steps for put operation of HashMap.
Step-1: Calculate the hashcode of the Key.
Step-2: Find the Bucket index for putting the entry.
Bucket index= (n – 1) & hashcode of key.
Step-3: If the Bucket is empty, put the new entry.
Else if there are entries in the Bucket.
Check if any existing entry is there for the same key by using equals() method. If no such entries are there then put the entry at the end of the LinkedList.
If already an entry is there, then just replace the Value attribute of that entry.

Let us look into the flowchart of get(Object key) operation of HashMap.

Let us look into the flowchart of remove(Object key) operation of HashMap.

Time Complexity for HashMap Operations
For put, get and remove operations:
Best case is O(1), if all the Buckets contain maximum one Entry each.
Worst case is O(n), if all the entries are in one Bucket only. This may happen in case of incorrect hashcode implementation, wherein it just returns the same for all Objects.
For example, the below is an incorrect hashcode implementation.
public int hashCode() {
return 10;// it returns 10 for all.
}
HashMap changes in Java 8 for Handling the Worst Case O(n):
Until Java 7, HashMap implementations always suffered with the problem of Hash Collision, i.e. when multiple entries end up in the same bucket, entries are placed in a Linked List implementation, which reduces Hashmap performance from O(1) to O(n).
The Solution:
Improve the performance of HashMap under high hash-collision conditions by using balanced trees rather than linked lists to store map entries.This will improve collision performance for any key type that implements Comparable.
The principal idea is that once the number of items in a hash bucket grows beyond a certain threshold (TREEIFY_THRESHOLD), that bucket will switch from using a linked list of entries to a balanced tree. In the case of high hash collisions, this will improve worst-case performance from O(n) to O(log n), and when they become too small (due to removal or resizing) they are converted back to Linked List.
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
How to Iterate HashMap in Java ?
You can iterate over a HashMap in Java using various methods, such as using an enhanced for loop, using the keySet(), values(), or entrySet() methods, or by using Java 8’s Stream API.
import java.util.*;
import java.util.stream.*;
public class HashMapIterationExample {
public static void main(String[] args) {
// Create a HashMap with some key-value pairs
HashMap < Integer, String > hashMap = new HashMap < > ();
hashMap.put(1, "One");
hashMap.put(2, "Two");
hashMap.put(3, "Three");
hashMap.put(4, "Four");
// Iterate over the HashMap using entrySet()
for (Map.Entry < Integer, String > entry: hashMap.entrySet()) {
int key = entry.getKey();
String value = entry.getValue();
System.out.println("Key: " + key + ", Value: " + value);
}
// Iterate over the HashMap using Stream API
hashMap.entrySet().stream().forEach(entry -> {
int key = entry.getKey();
String value = entry.getValue();
System.out.println("Key: " + key + ", Value: " + value);
});
}
}Output
Key: 1, Value: One
Key: 2, Value: Two
Key: 3, Value: Three
Key: 4, Value: Four
Key: 1, Value: One
Key: 2, Value: Two
Key: 3, Value: Three
Key: 4, Value: FourChanges Implemented in HashMap across Different Java Versions
HashMap in Java has undergone various changes across different versions.
Here are a few notable ones:
- Java 7: Prior to Java 7,
HashMapused a linked list to handle collisions. However, in Java 7, it introduced a new implementation called “hash table with linked list buckets”. This approach improved performance by transforming linked lists into trees for buckets with a large number of entries. - Java 8: In Java 8,
HashMapreceived significant enhancements to handle collision resolution. When multiple entries collide, instead of using a linked list or a tree, it switches to using a balanced tree to improve performance. This change significantly reduces the time complexity of operations such asget(),put(), andremove()in the presence of collisions. - Java 9: With the introduction of red-black tree-based replacement for linked list-based replacement in Java 8, Java 9 brought further enhancements. It introduced the concept of “tree bins” where a bucket is transformed into a tree if it exceeds a certain threshold (currently set at 8). The tree-based implementation improves worst-case time complexity from O(n) to O(log n) for operations like
get(),put(), andremove(). - Java 16: In Java 16,
HashMapintroduced a new implementation based on nodes. This new implementation avoids the overhead of dealing with TreeNodes when the tree gets converted back to a linked list. The nodes implementation improves performance for small maps and reduces memory overhead.
Real-life Use Cases for HashMap in Java
HashMap in Java can be used for the below use cases:
- Caching Mechanism: HashMap is often used as a cache implementation. It allows quick and efficient lookup of previously computed values, eliminating the need to perform expensive calculations or database queries repeatedly.
- Indexing and Searching: HashMap is commonly used in search engines and databases for indexing and searching operations. It provides fast access to stored data based on unique keys, enabling efficient retrieval of information.
- Data Storage and Retrieval: HashMap is widely used to store and retrieve data in various applications. For example, it can be used to store user preferences, configuration settings, or data retrieved from external sources like APIs or databases.
- Implementing Lookup Tables: HashMap can be used to create lookup tables, where values are associated with specific keys. This is useful in scenarios where quick access to information based on a particular key is required, such as mapping country codes to country names.
- Implementing Caches: HashMap can be utilized to implement various types of caches, such as in-memory caches or request/response caches. It allows storing frequently accessed data in memory for faster access, improving overall system performance.
- Associative Arrays: HashMap can be used as an associative array, allowing mapping of arbitrary keys to corresponding values. This is helpful in scenarios where data needs to be stored and accessed based on custom identifiers or labels.
- Multithreaded Environments: HashMap can be used as a thread-safe data structure by incorporating synchronization mechanisms like ConcurrentHashMap. This enables safe access and modification of shared data across multiple threads.
Best practices for using HashMap in Java
Here are some best practices for using HashMap in Java effectively:
- Use the appropriate initial capacity: When creating a HashMap in Java, it’s a good practice to provide an initial capacity that matches the expected number of elements. This helps avoid unnecessary resizing and improves performance.
- Override equals() and hashCode() methods: If you plan to use custom objects as keys in a HashMap, make sure to override the
equals()andhashCode()methods. This ensures that keys are properly compared and hashed, enabling correct retrieval of values from the HashMap. - Be cautious with mutable keys: HashMap keys should be immutable or effectively immutable to ensure consistency. If a key is mutable and its hash code or equality can change, it can lead to unexpected behavior or incorrect retrieval of values.
- Avoid excessive resizing: Frequent resizing of a HashMap in Java can impact performance. To mitigate this, estimate the maximum number of elements and set an appropriate initial capacity. Alternatively, you can use the
HashMap(int initialCapacity, float loadFactor)constructor to provide a higher load factor, reducing the frequency of resizing. - Use generics to specify key and value types: When declaring a HashMap in Java, it’s recommended to use generics to specify the key and value types explicitly. This enhances type safety and eliminates the need for explicit type casting.
- Understand thread-safety considerations: By default, HashMap is not thread-safe. If you need to use it in a multi-threaded environment, consider using ConcurrentHashMap or employing synchronization mechanisms like explicit locks or concurrent collections to ensure thread-safety.
- Minimize unnecessary object creation: Creating excessive temporary objects as keys or values can impact performance and increase memory usage. Avoid unnecessary object creation within the key-value pairs stored in the HashMap.
- Prefer foreach over iterator: When iterating over the key-value pairs of a HashMap, using a foreach loop (
for (Map.Entry<K, V> entry : map.entrySet())) is generally preferred over using an iterator. It provides a more concise and readable syntax.
When not to use HashMap in Java
Here are some cases where you may consider alternatives to HashMap in Java:
- Thread-safety requirements: If you require thread-safe access to a map, where multiple threads can concurrently modify it, HashMap is not the appropriate choice. In such cases, you can consider using concurrent data structures like ConcurrentHashMap or synchronized collections.
- Ordered data: If you need to maintain a specific order of elements, HashMap may not be suitable. HashMap does not guarantee any particular order of elements. Instead, you can use LinkedHashMap, which maintains the insertion order, or TreeMap, which provides a sorted order based on the keys.
- Memory efficiency: If memory usage is a concern and you have a large number of key-value pairs with low memory constraints, HashMap might not be the optimal choice. In such cases, you can explore more memory-efficient data structures like Trie.
- Immutable data: If you are dealing with immutable data, where the values associated with the keys do not change, using a HashMap might be unnecessary. Immutable data structures like ImmutableMap from Collections.unmodifiableMap() can provide a more efficient and safer solution.
FAQs
Q: What is a HashMap in Java?
A: HashMap is a class in Java that implements the Map interface. It is used to store key-value pairs, where each key is unique.
Q: How does HashMap work in Java?
A: HashMap uses a hash table to store the key-value pairs. It calculates the hash code of the keys and uses them to determine the index where the values are stored in an internal array.
Q: What is the difference between HashMap and Hashtable?
A: HashMap is not synchronized and allows null values and keys, whereas Hashtable is synchronized and does not allow null values or keys.
Q: How do you add elements to a HashMap in Java?
A: You can add elements to a HashMap using the put(key, value) method, where key is the key and value is the corresponding value.
Q: How do you retrieve a value from a HashMap?
A: You can retrieve a value from a HashMap using the get(key) method, where key is the key of the desired value.
Q: How do you remove an element from a HashMap?
A: You can remove an element from a HashMap using the remove(key) method, where key is the key of the element to be removed.
Q: How do you check if a HashMap contains a key?
A: You can check if a HashMap contains a key using the containsKey(key) method, which returns true if the key is present in the HashMap.
Q: How do you iterate over a HashMap in Java?
A: You can iterate over a HashMap using methods like keySet(), values(), or entrySet() and then using loops like for-each or iterators.
Q: How does HashMap handle collisions?
A: HashMap handles collisions by using chaining, where multiple entries with the same hash code are stored in a linked list or a tree.
Q: What is the default initial capacity and load factor of a HashMap in Java?
A: The default initial capacity of a HashMap in Java is 16, and the default load factor is 0.75.
Q: Can I have duplicate keys in a HashMap?
A: No, HashMap does not allow duplicate keys. Each key must be unique.
Q: How do I check if a HashMap is empty?
A: You can check if a HashMap is empty using the isEmpty() method, which returns true if the HashMap contains no key-value mappings.
Q: Can I store null values in a HashMap in Java?
A: Yes, HashMap allows storing null values. However, keep in mind that only one null value can be associated with a key.
Q: What happens if I try to retrieve a value for a non-existent key?
A: If you try to retrieve a value for a non-existent key using the get(key) method, it will return null.
Q: How can I get the number of elements stored in a HashMap?
A: You can get the number of elements in a HashMap using the size() method, which returns the count of key-value mappings.
Q: Can I modify the value associated with a key in a HashMap?
A: Yes, you can modify the value associated with a key in a HashMap by using the put(key, value) method. If the key already exists, the value will be updated.
Q: Does HashMap maintain the insertion order of elements?
A: No, HashMap does not guarantee the preservation of insertion order. If you need to maintain the order, you can use LinkedHashMap.
Q: How can I clear all elements from a HashMap?
A: You can clear all elements from a HashMap using the clear() method, which removes all key-value mappings.
Q: Can I use objects of custom classes as keys in a HashMap?
A: Yes, you can use objects of custom classes as keys in a HashMap. To do so, make sure to override the hashCode() and equals() methods in your custom class.
Q: How does HashMap in Java handle rehashing?
A: HashMap automatically rehashes its contents when the number of elements exceeds the product of the load factor and the current capacity. Rehashing involves resizing the internal array and redistributing the elements.
Conclusion: HashMap in Java
In conclusion, HashMap in Java is a versatile and powerful data structure that offers efficient storage and retrieval of key-value pairs. It provides a convenient way to organize and access data based on unique keys, making it a popular choice for various applications.
Best explanation and superb flowchart to explain detail concepts in HashMap. I have never seen such detailed explanation of HashMap in any other site.
Thanks Gyan for covering all these concepts.
I would like to add one thing here,
MIN_TREEIFY_CAPACITY = 64
The smallest table capacity for which buckets may be treeified. (Otherwise the table is resized if too many nodes in a bucket) Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts between resizing and treeification thresholds. If hashCode method is written improperly so that every entry falls under same bucket, then rehashing would never happen, only resizing will happen.
Thanks for the comments Vivek…Also thanks for mentioning MIN_TREEIFY_CAPACITY